flagger 应用自动发布组件 官网地址
https://github.com/weaveworks/flagger
官方介绍 Flagger can be configured to automate the release process for Kubernetes workloads with a custom resource named canary.
支持的 custom resource(即下文中的 provider) - istio
- Linkerd
- App Mesh
- Nginx
- contour
- CNI
- Kubernetes
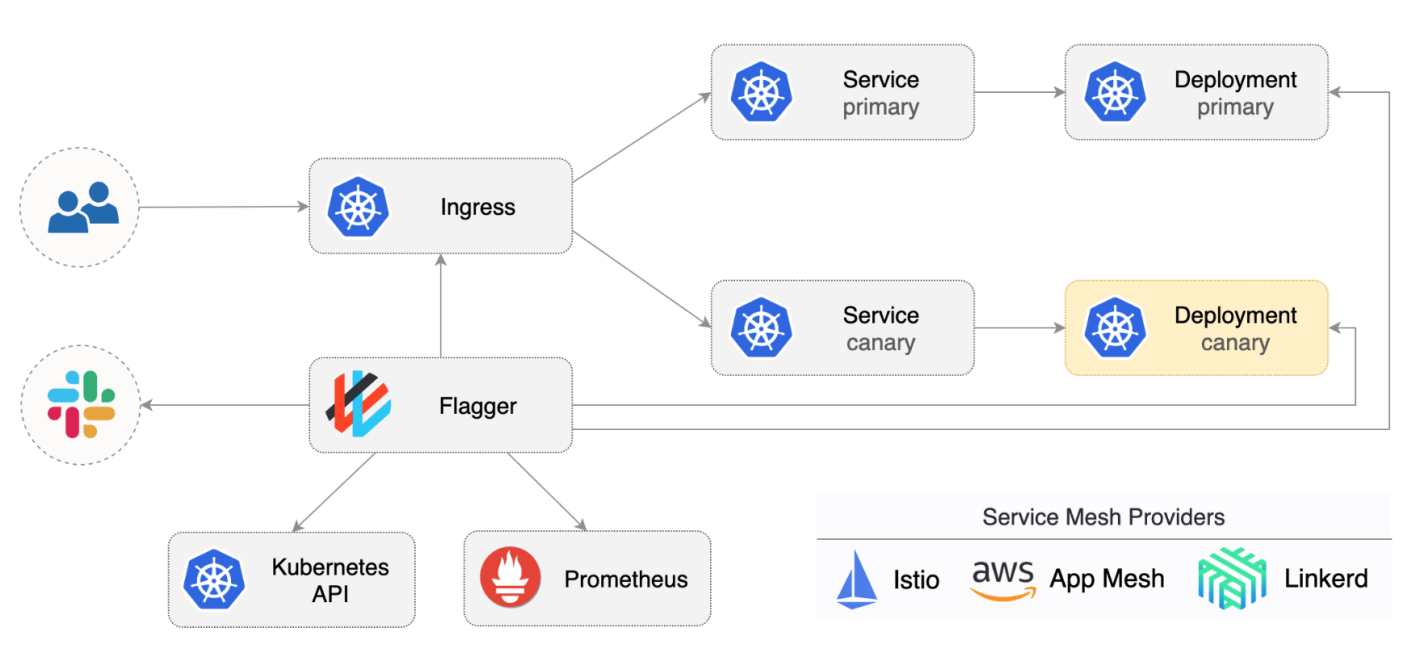
组件架构图 架构图解释 - primary service:已发布的在线服务(旧版本)
- canary service: 即将发布的新版本服务(新版本)
- Ingress:发布过程中发布粒度控制的 提供者
- Flagger:通过Flagger Spec 以 提供者提供的规范来调整 primary 与 canary 的 流量/副本运行 策略。调整过程中,根据 prometheus 采集的各项指标来决策是否回滚发布 或者 继续调整 流量/副本运行 比例。!!!此过程中,用户可自定义是否人工干预、审核、通知等动作。
示例 yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 apiVersion: flagger.app/v1beta1 kind: Canary metadata: name: podinfo namespace: test spec: provider: istio targetRef: apiVersion: apps/v1 kind: Deployment name: podinfo progressDeadlineSeconds: 60 autoscalerRef: apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler name: podinfo service: name: podinfo port: 9898 targetPort: 9898 portName: http portDiscovery: true match: - uri: prefix: / rewrite: uri: / timeout: 5s skipAnalysis: false analysis: interval: 1m threshold: 10 maxWeight: 50 stepWeight: 5 metrics: - name: request-success-rate thresholdRange: min: 99 interval: 1m - name: request-duration thresholdRange: max: 500 interval: 30s - name: "database connections" templateRef: name: db-connections thresholdRange: min: 2 max: 100 interval: 1m webhooks: - name: "conformance test" type: pre-rollout url: http://flagger-helmtester.test/ timeout: 5m metadata: type: "helmv3" cmd: "test run podinfo -n test" - name: "load test" type: rollout url: http://flagger-loadtester.test/ metadata: cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/" alerts: - name: "dev team Slack" severity: error providerRef: name: dev-slack namespace: flagger - name: "qa team Discord" severity: warn providerRef: name: qa-discord - name: "on-call MS Teams" severity: info providerRef: name: on-call-msteams
基本使用
- targetRef: 当前部署的新版本服务(可以是Deployment, 也可以是DaemonSet).
- progressDeadlineSeconds: canary, primary 部署超时时间.如果超过这个时间还没有部署好, 则不会进行 流量/组件副本 调整.
- autoscalerRef: K8s原生的HPA (自动伸缩).
- service: k8s service。当provider是Istio时, 和VirtualSercice(具有调整流量比例,路由策略等能力)相对应
- skipAnalysis: 是否跳过metrcis分析. 如果为true, 相当于一次性将primary替换成canary service.
分析
analysis:
- 包含一些调整primary, canary流量策略配置
- metrics: 指标来源. 例如: avg RT, 成功率, 自定义metrics(可以直接配置prometheus PQL)等
- webhook:可以用来人工审核接入, 压力测试等.
- alerts: 进度详情, 告警通知等
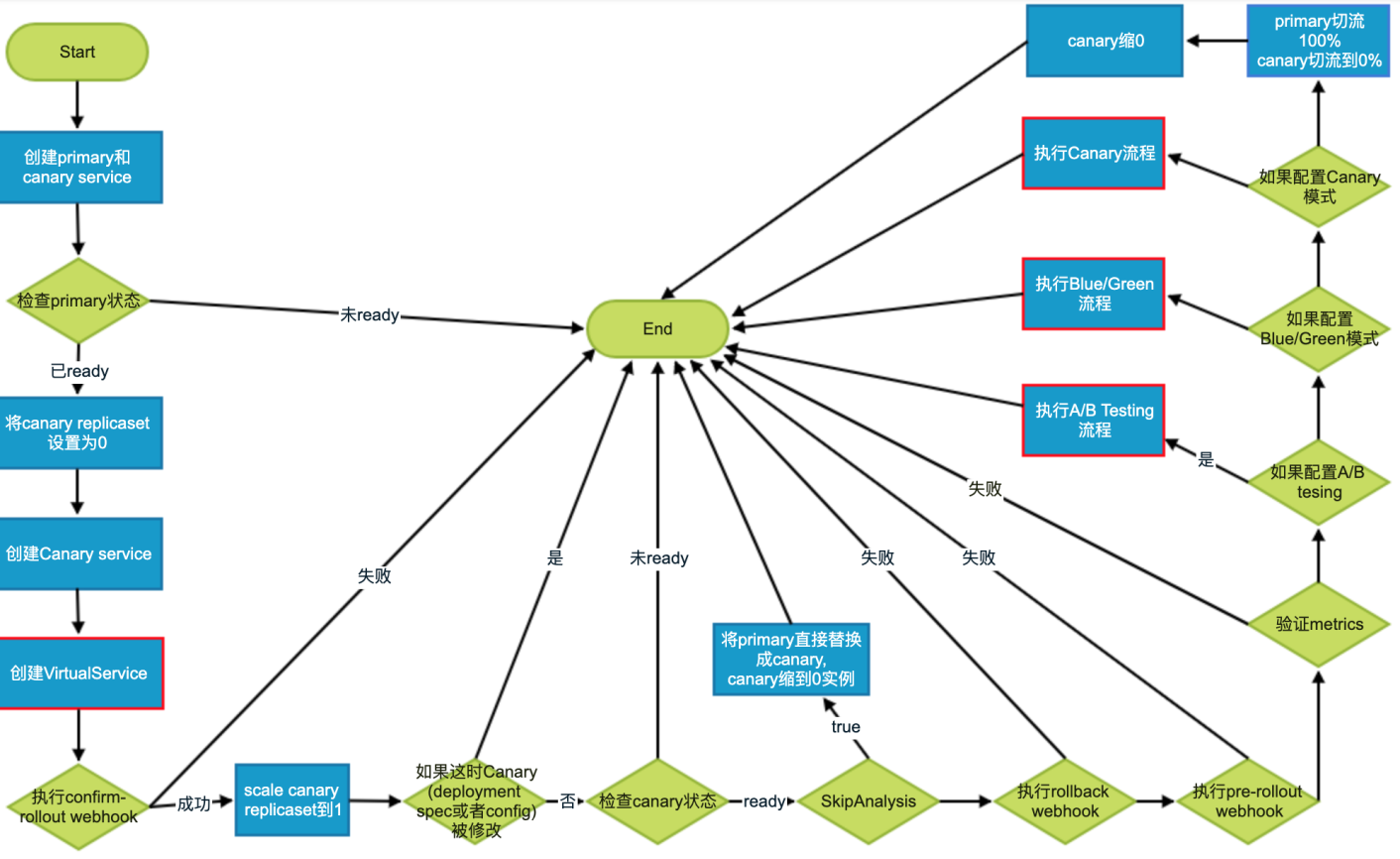
flagger 工作流程 !核心:webhook——人工干预,实现暂停、回滚、继续、策略调整
部署策略 A/B testing 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 analysis: interval: 1m iterations: 10 threshold: 2 match: - headers: x-canary: regex: ".*insider.*" - headers: cookie: regex: "^(.*?;)?(canary=always)(;.*)?$"
以上面代码示例为例:
1 2 • 如果是, 会将primary替换成cananry的spec(deployemnt spec, configmap)相关信息 • 如果否, 继续等待
Blue/Green 1 2 3 4 5 6 7 8 9 10 11 12 13 analysis: interval: 1m iterations: 10 threshold: 2 webhooks: - name: "load test" type: rollout url: http://flagger-loadtester.test/ metadata: cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
以上面代码示例为例:
1 2 • 如果是, 会将primary替换成cananry的spec(deployemnt spec, configmap)相关信息 • 如果否, 继续等待
如果配置了mirror=true(只有provider=istio时才支持该特性), 则会使用istio的mirror特性, 将流量分别copy 到primary和canary, 使用primary的reponse作为返回值. 这个时候要特别注意业务是否幂等.
Canary 1 2 3 4 5 6 7 8 9 10 11 12 13 14 analysis: interval: 1m threshold: 2 maxWeight: 50 stepWeight: 2 skipAnalysis: false
以上面代码示例为例:
1 2 • 如果是, 会将primary替换成cananry的spec(deployemnt spec, configmap)相关信息 • 如果否, 继续等待
其它 Webhooks webhooks: 在整个发布过程中, 定义了相应的扩展点:
Metrics Metrics: 用于决策(A/B, Blue/Green, Canary)流量是否验证失败, 超过制定阀值(threshold)就会回滚发布
1 2 3 4 5 6 7 8 9 10 11 12 13 14 analysis: metrics: - name: request-success-rate interval: 1m thresholdRange: min: 99 - name: request-duration interval: 1m thresholdRange: max: 500
request-success-rate(请求成功率). 上例说明成功率不能低于99%
request-duration(avg RT): RT均值不能超过500ms
不同的provider有不通实现. 例如:应用可以提供prometheus metrics
• 自定义metrics
创建MetricTemplate. 比如业务自定义的业务metrics, 如订单支付失败率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 apiVersion: flagger.app/v1beta1 kind: MetricTemplate metadata: name: not-found-percentage namespace: istio-system spec: provider: type: prometheus address: http://promethues.istio-system:9090 query: | 100 - sum( rate( istio_requests_total{ reporter="destination", destination_workload_namespace="{{ namespace }}", destination_workload="{{ target }}", response_code!="404" }[{{ interval }}] ) ) / sum( rate( istio_requests_total{ reporter="destination", destination_workload_namespace="{{ namespace }}", destination_workload="{{ target }}" }[{{ interval }}] ) ) * 100
引用MetricTemplate
1 2 3 4 5 6 7 8 9 analysis: metrics: - name: "404s percentage" templateRef: name: not-found-percentage namespace: istio-system thresholdRange: max: 5 interval: 1m
上例表示canary的关于404错误/s的metrics不能超过5%
Alter Alter: 用于发布过程中信息通知.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: flagger.app/v1beta1 kind: AlertProvider metadata: name: on-call namespace: flagger spec: type: slack channel: on-call-alerts username: flagger address: https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK secretRef: name: on-call-url --- apiVersion: v1 kind: Secret metadata: name: on-call-url namespace: flagger data: address: <encoded-url>
2.使用Alter
1 2 3 4 5 6 7 analysis: alerts: - name: "on-call Slack" severity: error providerRef: name: on-call namespace: flagger
• serverity: 通知信息的等级, 类似日志级别. 包含info, warn, error
!使用 flagger 保证 0 宕机 所需 注意点 :
限制: 单纯 kubernetes CNI 仅支持 蓝绿发布
额外发布支持: NGINX 支持 金丝雀、A/B、蓝绿发布
ISTIO 所有发布类型支持
发布策略、动作支持 核心
webhook 支持以下
确认发布——confirm rollout(确认发布将开始)
预发布——pre-rollout(发布开始时确认动作)
发布每一步——rollout(每次发布变更步骤执行)
确认发布生效——confirm-promotion(确认发布将生效)
预生效——post-rollout(每次生效时确认动作)
回退——rollback(处于 发布中 /等待中 状态时可以执行回滚)
事件——event(发布过程中,发布相关事件都可以被监听,来执行对应的策略)
参考连接
https://docs.flagger.app/usage/webhooks